
Introduction
This article shows how easy it is to implement an advanced analytics use case in Fabric with Python code. The use case is about implementing a sentiment analysis of customer feedback from online shops. It explains how to develop a notebook in Microsoft Fabric for the execution of advanced analytics tasks. It will also illustrate how easily we can integrate these advanced analytics tasks into pipelines for daily planning.
Description of the use case
We regularly receive customer information via a web shop, which is stored in a structured table on a Fabric Lakehouse. This customer feedback is very important information for the company and business in order to continuously improve customer satisfaction. A sentiment score is calculated for these customer comments. This score measures how positive or negative a customer comment is.
The following business value can be achieved through this use case:
- The score can be used to classify a comment as ‘positive’ or ‘negative’. This can be used as a filter in a dashboard, for example, so that management can display only positive or negative comments in a filtered manner.
- The sentiment scores can be used to prioritise responses to comments. For example, a lower response time can be defined as an SLA for very negative comments.
Positive and negative comments can be analysed grouped by product category, media channel or other attributes. This allows patterns and/or trends to be analysed.
Data basis for the analysis:
The basis for the analysis is a delta table on the Fabric-Lakehouse. This is a simulated dataset; the names and other content are randomly simulated and automatically generated.
This screenshot shows the most important information and attributes of the table:
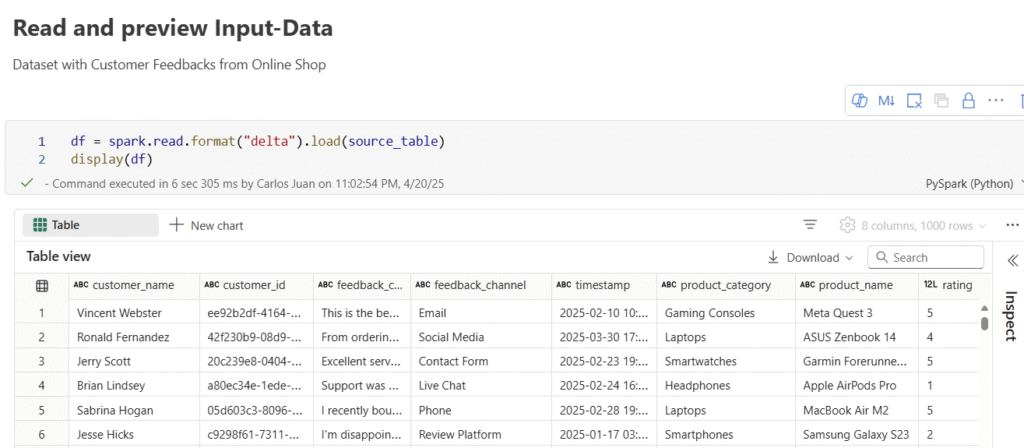
Further information is available for each customer comment, including the specific time stamp of the comment entry, customer name and ID, the channel via which the comment was received and the product category of the comment.
Setup and libraries
For the implementation we use Fabric-Notebooks executed on a Spark-Cluster. There are several libaries relevant, including the textblob library. TextBlob is an open-source Python library for processing text data. The library already provides out-of-the-box models, including for sentiment analysis of texts.
We use this package for sentiment analysis. Users with a Fabric Capacity = F64 or higher can also use the new Fabric AI functions instead. However, as these can only be used from a large capacity, I am using an open source solution for this article.
The required libraries are installed and loaded at the start of the notebook:
Definition of parameters
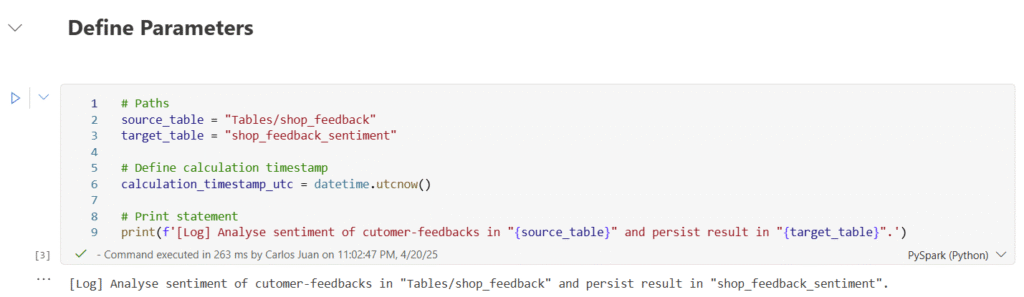
The next step is to define upstream parameters. A basic distinction can be made between static and dynamic parameters. In this code block, source and target tables are defined and a central timestamp is created for the calculation date of the sentiment analysis.
It makes sense to create this timestamp centrally upstream instead of on-the-fly when writing the target table, as partitioned writing of the target table can result in small deviations in the timestamps per partitioning. In addition, a print of the data flow is output; it is generally advisable to output several prints in important steps, as this can significantly simplify debugging and troubleshooting.
Definition of the functions
In the next step, the functions for the script can be defined in a separate cell block. In this use case, only one function is defined; in more complicated use cases, several functions are often relevant.
If functions are used across different notebooks, it can be useful to define these functions in a central utils notebook or to define the functions as a user-defined function in Fabric. This ensures consistency and reuse.
Back to the use case. Here is the relevant function for sentiment analysis:

As already described in the docstring of the function, a string is expected as input to the function, in our case the customer comment. The sentiment score is then calculated for this string based on the TextBlob Library function. In addition, a categorical value is subdivided into the sentiment ‘positive’, ‘negative’ and ‘neutral’, depending on the respective sentiment score.
Calculation of sentiments and persisting of results
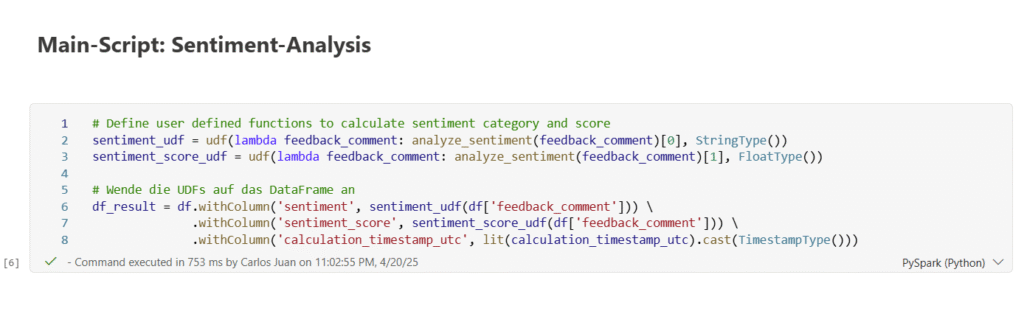
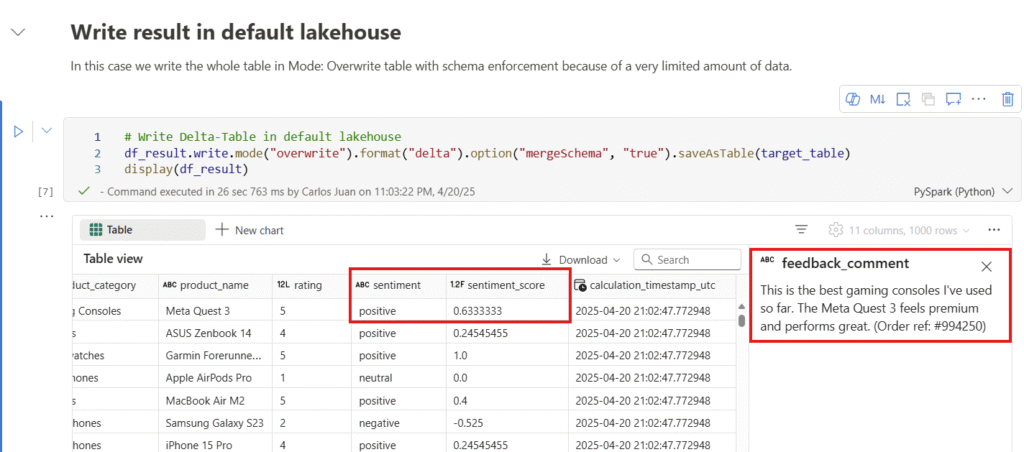
In this Code-Block the sentiments and sentiment-scores will be calculated by executing the pre-defined function. A new spark-data-frame is defined as df_result with the added result columns. After successful calculation we write the result-data-frame as delta-table in our target lakehouse.
As we can see in the screenshot we have calculated a sentiment_score and a derived sentiment for each customer feedback. In the example we have Feedback about Meta Quest 3 product and the feedback is interpreted as highly positive.
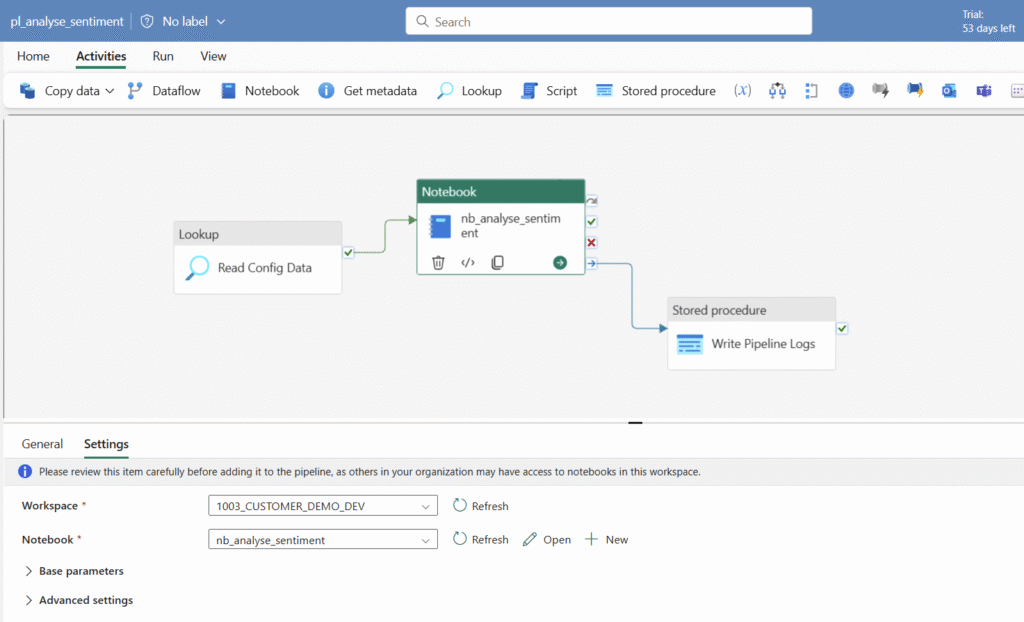
Orchestration of notebook
The Fabric Notebook artifact can be simple orchestrated through data factory pipelines. To do this, we can simply create a pipeline in Fabric and add the notebook as a task. In an expansion stage, it is recommended to add further tasks in the pipeline, such as reading config information as input for the notebook or writing log information, e.g. on the Fabric integrated SQL DB.
Limitations and potential improvements
The use case is implemented very simply and some improvements or extensions could be made. Firstly, Spark Streaming Functions could be used for reading and writing the data. This would allow the new data to be processed incrementally. Furthermore, a Spark cluster configured specifically for the use case could be used directly. For reasons of cost savings, the cluster could possibly also be used as a pay-as-you-go service. With a capacity size of F64 or larger, the fabric-native AI functions could be used. It would also be useful to use a training set with labelled data to assess the overall model quality. Other models could be used to compare the different model qualities against each other.