
Introduction
Microsoft Fabric has released AI agents as a new service for its data and AI platform. The service is currently (as of August 2025) still in public preview and will certainly be expanded further. Nevertheless, I have already tested the AI agents in detail and examined the added value they offer and the limitations that should currently be taken into account.
For the review of the Data agents, I have formulated a number of research questions that I would like to explore in more detail in my article. Firstly, I would like to examine the service from a technical perspective as a developer:
- How easy is it to set up an AI agent in Fabric?
- Which settings/parameters can I already configure individually as a developer?
- What options do I have as a developer to manage an AI agent, e.g., view query history?
- What limitations currently exist?
Second, out of personal interest, I would like to explore the question of whether AI agents can already generate business value at this stage of maturity. My simple general question here is, which business value we have to expect from the data agents now and in future.
Setting up a Fabric Data Agent
The standard setup for a Data Agent is extremely simple and is described very well in the Microsoft documentation. For this reason, this article will not go into detail about the setup step by step. In short, an AI agent can be created from the UI, and then data sources, such as a semantic model or lakehouse tables, can be assigned to the AI agent, on the basis of which the AI should answer user questions.
The Data Agent service can be found in the Fabric User interface:
For my review, I created a small lakehouse with sample data. The sample data provides a fact table with sales bookings and common dimension tables. The tables can then be easily assigned to the agent as sources. In this case, I select all tables as sources for the agent, as they are directly related to my use case/agent.
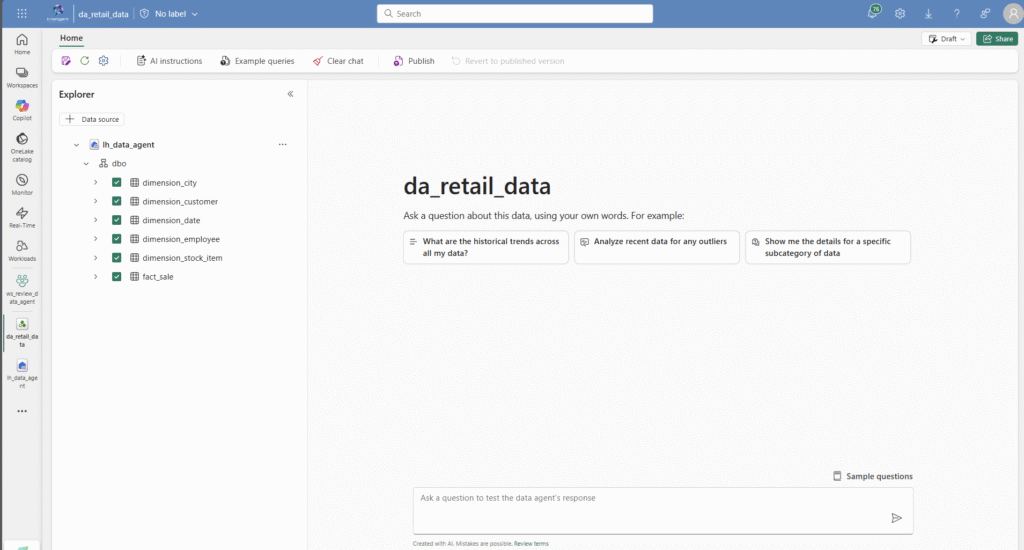
Then the basic setup is complete. Now I can already ask questions via the chat window and chat with the data. The basic setup is very simple, and I question whether the setup can be carried out in this way in an enterprise context. However, I will comment on this in more detail later.
Evaluation of the business case for data agents
I asked myself what the actual added value of a data agent is, and in my opinion, this question is not so easy to answer. Strictly speaking, I have the data available and can write ad hoc queries with SQL or Python or visualize recurring analysis questions in PowerBI reports. So what is the business added value if analytical questions about my data can be asked using natural language?
One added value is that, simply put, it saves time. Instead of having to write an SQL query, you can just ask the specific question in the text and the agent neatly compiles all the relevant information. However, thanks to ChatGPT, SQL queries are now easy for the general public to write.
For me, the key added value at present is the easy accessibility of information for the business. People with less IT affinity can simply chat with the data instead of writing programmed queries. In my view, this added value is not clearly quantifiable but should not be underestimated. Often, the barriers to the efficient use of data in business are very high, and this is why decisions often made without efficient usage of data even nowadays. If the data can be used and analyzed so easily by everyone in the business, it can take the use of data to a new level.
In my opinion, the use cases for data agents will become much more extensive in the future. Data agents could also be integrated directly into business processes via API requests. This would allow data-based decisions and follow-up processes to be initiated based on responses from the data agents, for example.
Parameterization and configuration options
As a developer in the enterprise environment, I am naturally interested in the options available for viewing what is happening under the hood and what I can configure individually on the agent.
First of all, I have the option of defining agent instructions. This can be understood as a system prompt in which I can configure how the agent should proceed when answering user questions. Here a simple example:
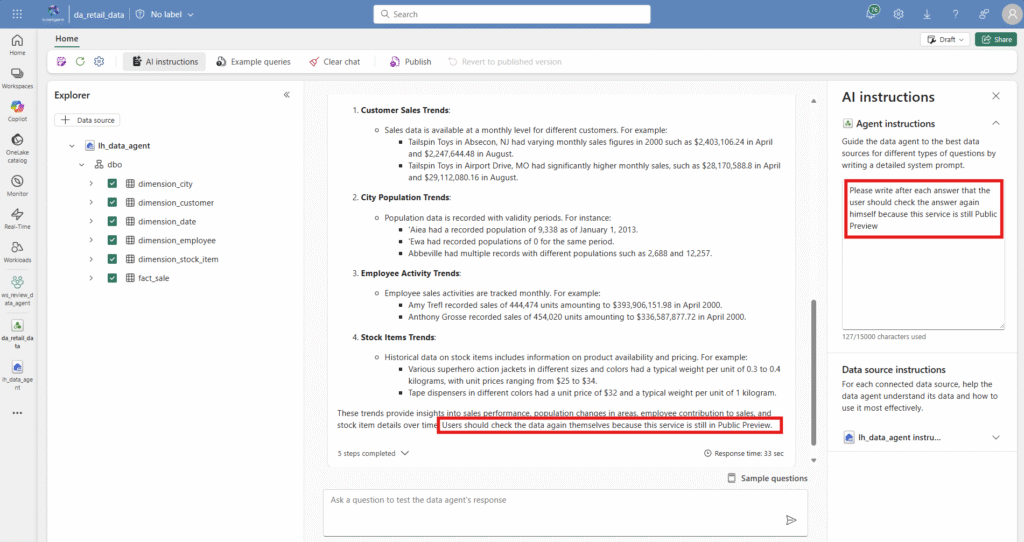
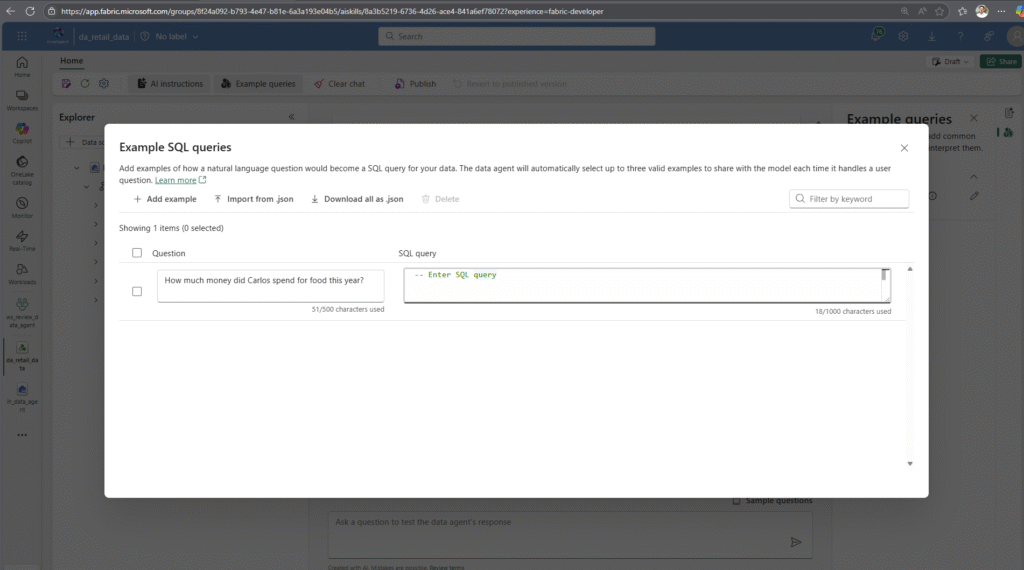
I also have the option of improving the agent by defining sample questions with associated queries. This allows me to cover company-specific special cases, for example. This functionality enables the Data Agent to learn data-specific relationships.
Last but not least, I have the option to publish the Data Agent for general use. This gives me the option to share access to the agent via item permissions:
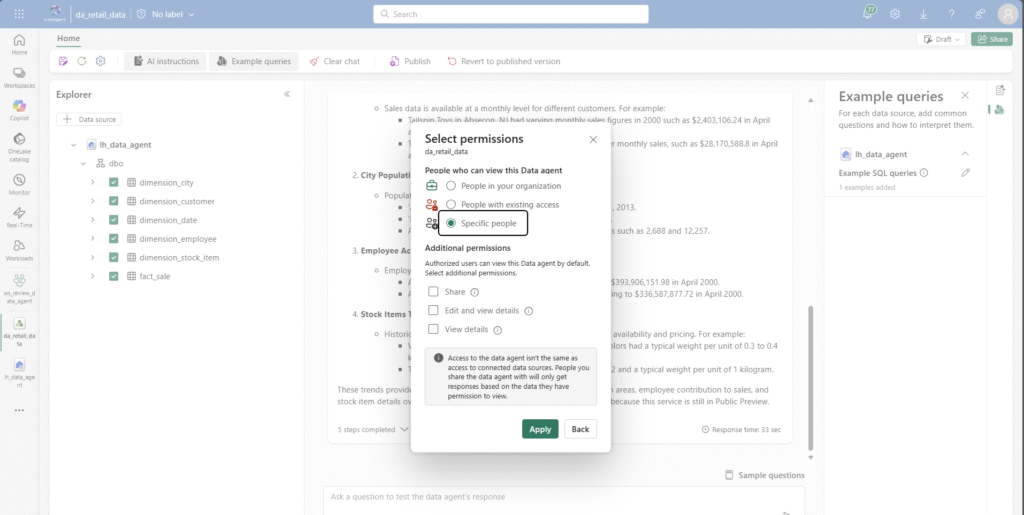
Another great feature is that the data agents already take into account whether a user has access to the connected data sources and only respond to individual users based on their data permissions. However, I have not yet tested in detail whether RLS/CLS can also be taken into account.
Critical assessment
As a developer of data platforms, I definitely feel that some technical parameters are missing. I created the item/data agent with my personal user account. If the data agent is used productively, I believe this should be done with a service principal for reasons of reliability. This would probably require an approach using Terraform or Rest API for provisioning.
In addition, I assume that multiple environments, e.g., Dev/Test/Prod, may be required for productive use in an enterprise context. For example, you want to evaluate the agent quality with A/B testing on Dev before putting changes to the configuration into production. It is unclear to me how the deployment and the CICD process can be guaranteed with current resources.
Another question that remains open for me is how I, as the IT manager in an organization, can support and monitor these data agents. As an administrator, I would like to have more options here. For example, it would be important to have access to the queries and answers and to be able to persist them. This would allow access to the history in support cases. In addition, the queries could be analyzed and the insights could be used to improve the agents, f.e. unsolved questions could be added with solution as example queries.
The functionality of the agent and the underlying language model can currently only be influenced by the system prompt. The underlying LLMs cannot be selected either. More extensive functionalities for influencing the model, such as fine-tuning, are not available. However, it is also questionable whether this is necessary for the standard use cases for Fabric Data Agents. AI Foundry can also be used for more complex requirements.
Conclusion
I believe that Data Agents in Fabric can offer significant added value for business users. Accessibility to working with data is greatly simplified, which reduces the barrier to using data in all areas of business. This factor can have an enormous positive effect on an entire organization, and it is essential that companies address this topic in future.
A standard Fabric Data Agent can already answer simple questions about well-prepared data. In more complex and business-specific contexts, the standard setup reaches its limits. However, system prompts and sample queries for the agent can be used to create context.
Data agents in Fabric can be set up very simply, but there are still some technical limitations. Companies need to assess whether these technical limitations are acceptable or whether criteria for productive use have not yet been met.